
Нахождение последнего элемента списка
Одним из наиболее часто используемых способов организации информации в памяти ЭВМ является ее представление в виде списков, которые позволяют оперировать не с самими величинами, а с их адресами, что облегчает программирование, экономит память и сокращает затраты на пересылку информации. С помощью списков удобно отображать данные самой разнообразной структуры: множества, деревья, графы, строки и т.д.
Основными операциями над списками являются: получение доступа к произвольному элементу списка; включение нового элемента в заданное место списка и исключение его оттуда; сортировка элементов списка; поиск элемента с заданными свойствами и другие. Простота их реализации является одним из наиболее привлекательных свойств списковой организации данных. Однако традиционное представление списков на основе ссылок предполагает последовательную обработку их элементов. Все известные алгоритмы, реализующие операции над списками, являются последовательными и ориентированы на однопроцессорные ЭВМ фон-неймановской архитектуры.
Эффективная реализация операций над списками для параллельных вычислительных систем представляет непростую (а для некоторых архитектур — например, векторно-конвейерной — и неразрешимую) задачу. Особый интерес представляла бы разработка таких алгоритмов для ВС с большим числом процессорных элементов.
Под списком L будем понимать совокупность объектов вида In =(V, C), где V — ссылка на данные, C — ссылка на некоторый (следующий) элемент этого же списка. Последний элемент списка имеет своим значением nil, т.е. пустую ссылку.
Пусть элементы каждой двойки (V, C) расположены в памяти так, что их адреса определяются сложением фиксированного смещения с некоторым базовым адресом. Тогда совокупность всех двоек можно рассматривать как массив R — образ списка, в котором места расположения каждого элемента могут быть рассчитаны.
Интуиция подсказывает, что параллельная обработка списка невозможна, поскольку в общем случае необходимо вычислить адреса k предыдущих элементов списка, прежде чем станет доступен (k+1)-й элемент.
Однако, она становится возможной, если использовать образ списка.
Модифицируем представление каждого элемента массива R, введя дополнительное поле D, в которое заносится ссылка на соответствующее поле того элемента списка, ссылка на который содержится в поле C. Строить образ списка целесообразно одновременно с формированием и изменением самого списка. Таким образом, элемент образа списка превращается в тройку (F, C, D). На рис. 1.1
структура элемента образа списка представлена в графической форме.
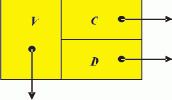
Рис. 1.1. Элемент образа списка
На рис. 1.2,а изображен список, соответствующий записи L = (A B E F G H Г) (для простоты считаем, что он не содержит подсписков).
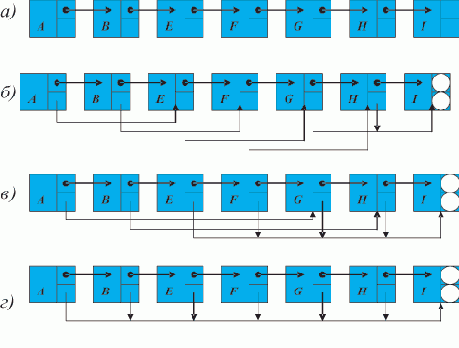
Рис. 1.2. Пошаговое нахождение последнего элемента списка (последовательное расположение элементов в памяти)
Пусть над всеми его элементами последовательно, начиная с головы, производится следующее действие: поле D текущего элемента принимает значение того поля D, на которое указывает содержащаяся в нем ссылка (если в поле D содержится ссылка на пустой элемент, то его значение не изменяется). В результате список L примет вид, показанный на рис. 1.2,б. Вид списка L после второго прохода показан на рис. 1.2,в. И, наконец, после третьего прохода поле D головы списка будет содержать ссылку на последний элемент списка L, на чем выполнение алгоритма заканчивается (рис. 1.2,г).
Предположим теперь ситуацию, когда элементы списка расположены в памяти в произвольном порядке, например, так, как показано на рис. 1.3,а.
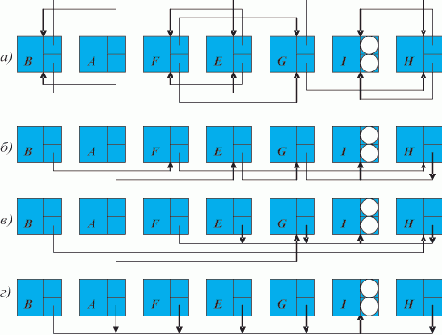
Рис. 1.3. Пошаговое нахождение последнего элемента списка (произвольное расположение элементов в памяти)
Важно, что преобразования не изменяют структуру списка, поскольку действия производятся над "избыточной" информацией; при этом на правильность выполнения алгоритма не влияет порядок расположения элементов в памяти.
Заметим теперь, что все операции над образом списка R, производимые во время одного прохода, могут быть выполнены параллельно и независимо друг от друга, то есть, при наличии достаточного вычислительного ресурса, за один временной шаг.
Таким образом, мы получаем доступ к последнему элементу списка за log2N шагов. Аналогичные алгоритмы, также использующие информационную избыточность, могут быть построены и для других операций над списками.
Реализация операций над списками для локально-асинхронной ВС, каковой является ВС SPMD-архитектуры, допускает использование принципа монопрограммирования, т.е. составления единственной программы, запускаемой на всех процессорах одновременно. Здесь мы приведем монопрограмму нахождения последнего элемента списка и проследим процесс ее выполнения. Она выбрана потому, что нахождение последнего элемента является частью многих операций над списками. Например, для объединения списков L1 и L2 достаточно найти последний элемент списка L1 и заменить в его поле C пустую ссылку ссылкой на первый элемент списка L2.
Как говорилось выше, для организации параллельной обработки целесообразно использовать образ R списка — массив информации об элементах списка, содержащий сведения о его структуре и преемственности элементов. Отметим, что упорядоченность элементов массива R в памяти в общем случае может не совпадать с логической упорядоченностью элементов списка, задаваемой ссылками. Это позволяет достаточно просто интерпретировать выполнение операций над списками. Например, при добавлении новых элементов в список L нет необходимости вставлять новый элемент массива R в какую-либо конкретную позицию - можно просто добавить его в конец массива. Аналогично, при исключении элемента из L вместо уплотнения массива R на освободившееся место можно записать его последний элемент.
Обработку списка, таким образом, мы сводим к обработке массива, представляющего его образ. Этот массив, в свою очередь, может описываться дескриптором.
Дескриптор DR массива R={V,C,D}1^N в полной комплектации, как рассматривалось ранее, состоит из восьми элементов: DR={DRO , ..., DR7}. Дескрипторный элемент DRO содержит адрес a0 первого элемента массива, DR1 — шаг h = 3 переадресации, DR2 — количество N элементов массива, в DR3 находится адрес последнего элемента массива.
Элемент DR4 служит для переадресации при последовательном обращении к данному массиву. В нем хранится адрес aQ+jh для выработки элемента массива при j-м (j = 0,1 , ..., n-1) обращении к массиву. При каждом обращении к массиву по некоторым командам этот адрес увеличивается на шаг h (т.е. выполняется операция j := h+!). Остальные дескрипторы предназначены для организации распределения элементов массива между процессорами. DR5
содержит значение адреса aQ+ih, i = 0,1 , ..., n-1, т.е. каждый процессор Пi формирует и использует свое значение (DR5), располагая адресом регистра, содержащего значение номера i процессора, для начального обращения к "своему" элементу массива. DR6 содержит значение nh, используемое для переадресации к следующему "своему" элементу массива с учетом числа процессоров в ВС. В DR7 содержится значение адреса aQ+ih+jnh=(DR5)+j(DR6), используемое для возможности переадресации при последовательном (j = 0,1,...) обращении к массиву. Если нет необходимости, могут формироваться не все дескрипторные элементы.
Предположим, как и ранее, что в ВС реализована трехадресная система команд вида: ? I1 A1 12 A2 I3 A3, где ? — код операции, I1, I2, I3 — адреса модификаторов, дескрипторных элементов или дескрипторов, A1, A2, A3 — смещения. При выполнении команд формируются исполнительные адреса: A'r =(Ir)+ Ar, r = 1,2,3.
Для упрощения операций над дескрипторами в систему команд введены специальные команды, обеспечивающие переадресацию для различных дисциплин выбора "своих" элементов обрабатывающим процессором, анализ выхода за пределы массива, инвариантность программы относительно размера массива.
Монопрограмма нахождения последнего элемента списка представлена в табл. 1.2.
| СИНХ | ||||||
| ЗАГ | K | |||||
| ПРАД | DR7 | 012 | ||||
УП | K | 012 | ||||
| ЗАПК | DR7 | 0003 | M | |||
| УП=0 | M | 011 | ||||
| ЗАПК | M | DR7 | 0003 | |||
| ИЗМАД | DR7 | 009 | ||||
| БП | 003 | |||||
| ЗАГ | DR7 | DR5 | ||||
| БП | 0003 | |||||
| ЗАП | DR7 | 0003 | K | |||
| В |
Каждый процессор посылает сигнал на устройство СИНХ; после поступления сигналов от всех процессоров выдается обратный сигнал, по которому процессоры приступают к выполнению следующей команды.
Команда 1 (ЗАГрузка модификатора) обнуляет модификатор K, в который впоследствии одним из процессоров будет записан адрес последнего элемента списка.
Команда 2 (ПРоверка АДреса) сравнивает значение дескрипторного элемента DR1, первоначально равное a0+3i, с адресом последнего элемента массива, записанным в дескрипторном элементе DR3. Этим устанавливается возможность загрузки i-го процессора (возможен случай i>N). Если процессор не будет занят обработкой списка, то управление передается команде 12 на Выход из процедуры. В противном случае с команды 3 начинается цикл обработки элементов списка, а точнее — его последовательности ссылок. Команда 3 осуществляет Условный Переход на выход из процедуры по отличному от нуля значению K.
Команда 4 выполняется при нулевом значении K, она осуществляет ЗАПись по Косвенному адресу. При этом производится косвенное считывание по первому адресу (DR7) + 0003, т.е. по адресу ((DR7)+0003), и запись по адресу модификатора M.
Команда 5 проверяет, пуста ли выбранная ссылка. Если пуста, то анализируемый элемент списка - последний; управление передается команде 11, записывающей адрес этой ссылки в K. Если не пуста, т.е. (M)\neq 0, то выполняется команда 6 и ее значение записывается вместо значения текущей ссылки.
Команда 7 ИЗМенение АДреса задает операцию (DR7):=(DR7)+(DR6) и если полученное значение превышает (DR3), передает управление команде 9. Таким образом, каждый процессор осуществляет переадресацию для последующей выборки "своего" адреса ссылки из массива таких адресов. Если при этом массив не исчерпан, то команда 8 (Быстрый Переход) передает управление на команду 3 — продолжение цикла подстановки ссылок. Если переадресация выводит из массива, то команда 9 восстанавливает дескрипторный элемент DR7 , т.е. выполняется операция (DR7):= (DR5) = a0+3i.
По команде 10 управление передается на следующий цикл подстановки ссылок.
Команда 11 выполняется, если при выполнении команды 5 обнаружилось, что найдена пустая ссылка, адрес которой записывается в K. После выполнения в последующем команды 3 всеми процессорами закончится и выполнение программы.
Рассмотрим процесс счета программы нахождения последнего элемента списка L, содержащего семь элементов, на ВС, имеющей в составе три процессора — П0, П1 и П2.
Каждый процессор выполняет свою копию программы, обладая при этом собственным набором дескрипторов, отличающихся друг от друга только значениями дескрипторных элементов DR5 и DR7. Согласно принятому нами представлению образа списка и порядку его обработки, процессор П0 будет обрабатывать элементы списка A, F и I, процессор П1 — B и G, и процессор П2 — элементы E и H. Пусть каждая команда программы выполняется за одинаковое время — условный такт, и при обращении к памяти не возникает конфликтов (все элементы образа списка расположены в разных блоках памяти).
На рис. 1.4 показана диаграмма потактового выполнения программы на каждом из процессоров, полученная при справедливости этих предположений. Некоторое время все процессоры работают синхронно: такты 1—3 — начальные действия; такты 4—9 — первый цикл подстановки ссылок, во время которого изменяются поля D элементов A, B и E; такты 10—12 — начало второго цикла подстановки ссылок.
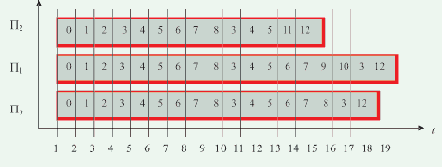
Рис. 1.4. Временная диаграмма выполнения программы нахождения последнего элемента списка
Во время второго цикла подстановки ссылок процессор П2 обнаруживает пустую ссылку (т.е. последний элемент списка) в такте 12 и, записав его адрес в модификатор K (такт 13), заканчивает свою работу в следующем такте командой Возврат.
Процессор П0 заканчивает второй цикл подстановки ссылок (такты 13—15), не обнаружив пустой ссылки, но завершает свою работу в тактах 16 и 17, поскольку модификатор K получил уже к этому времени ненулевое значение.
Процессор П1 в такте 14 изменяет значение дескрипторного элемента DR7 и, так как оно выводит за границы обрабатываемого массива, в такте 15 восстанавливает его исходное значение.
Далее следует переход на начало третьего цикла обработки ссылок (такт 16), но, обнаружив ненулевое значение модификатора K (такт 17), в следующем такте процессор П1 также завершает свою работу. Результатом совместной работы трех процессоров является адрес ссылки на последний элемент списка, записанный в модификаторе K.
Заметим, что детерминированный — при синхронной работе процессорных элементов — процесс выполнения алгоритма при реализации на локально-асинхронной ВС приобретает некоторую неопределенность. Дело в том, что мы не можем быть уверены в порядке выполнения процессорами операций замены значений ссылок (команда 6), поскольку в принципе не исключены обращения к одним и тем же модулям общей памяти. В результате какой-либо процессор может "подхватить" уже обновленную ссылку. Однако очевидно, что это только приблизит окончание работы алгоритма, который в таком случае как бы "перескакивает" через некоторые шаги. Например, элемент A, обрабатываемый процессором П0, после первого выполнения процессором команды 6 должен содержать ссылку на элемент E. Но если процессор П1 успел по какой-либо причине выполнить свою аналогичную операцию раньше, элемент A будет содержать ссылку на более "удаленный" от него элемент F. Поэтому появляется возможность более раннего достижения условия окончания работы программы.
Здесь иллюстрируется не всегда ясно сознаваемый факт, что принципы параллельной обработки информации могут быть использованы для нахождения самого общего решения задач, по своей природе, казалось бы, не распараллеливаемых. Эффективность параллельной обработки списков в данном случае достигается двумя встречными путями: дополнением традиционного подхода концепцией обработки массивов и использованием архитектурных особенностей ВС, реализующей SPMD-технологию.